Twitch
Twitch solves a couple unique problems, namely, live video streaming and large group chat.
Before we jump into examining how their streaming and chat work, we will cover some terminology and the basics of their site.
- Terminology
- General Architecture
- Notifications
- React
- Agolia Instant Search
- Messages
- Chat
- Video Streaming
- 2 Factor
- OAuth Connections
- Commerce
- Settings Page
- Video Producer
- WASM Service Worker
- Dashboard
- TL;DR
Terminology
- stream – can either be a session of live streaming or refer to a channel
- channel – page where a user can stream their content
- subscribe – users can pay ~$5, although there are multiple buy in levels, to unlock perks such as emotes, chat channels, discord servers, and more. Note: These perks can vary greatly between channels.
- vod – video of a past stream
- rerun – rebroadcast of a past stream, similar to a vod, but lacks a video scrubber and takes the place of the stream.
Note: values in text and URLs will sometimes be substituted with variables
in the form $(VAR_NAME), this helps with describing generalized formats, and
helps minimize the JSON examples.
General Architecture
For transferring data between their React App and backend, Twitch uses GraphQL.
When logged in, Twitch authenticates requests using an Authorization header.
Don’t worry, all those secrets are fake.
Request
POST /gql HTTP/1.1
Content-Type: text/plain;charset=UTF-8
Origin: https://www.twitch.tv
Host: gql.twitch.tv
Pragma: no-cache
Accept: */*
Connection: keep-alive
Accept-Encoding: gzip, deflate
Accept-Language: en-US
DNT: 1
Authorization: OAuth w8oa8myl28ttbx9r6hms9ayk8n
Content-Length: 195
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/11.1.2 Safari/605.1.15
Referer: https://www.twitch.tv/
Cache-Control: no-cache
Client-Id: 4qzwg0zmxv2xqddqoxnydzxbbyoezf
X-Device-Id: ptt47yco0ta1njsz
Storage & Resources
First off, there is a lot of stuff stored in sessionStorage, cookies, and especially localStorage.
Some notiable tid bits from localStorage include
Agolia search info, tracking and error reporting related data,
ad-block detection properties (blockDetector.detected: true), CSRF token,
video player settings, theme settings (the CSS class is stored as the
theme value).
In cookies, Twitch stores last login date, name, login, some unique identifiers (probably for tracking), along with a lot of settings referencing twilight, which I think is the name of their React app.
Twitch also uses a service worker. It has some connection to the URL https://spade.twitch.com.
If we dig into the minified source, we find the m() function which URL
encodes and POSTs to "https://spade.twitch.tv/", which is called twice:
m(d.SpadeEventType.NotificationImpression, t),
m(d.SpadeEventType.NotificationInteraction, t). Judging by those names, this
service working is probably used for tracking.
In the m() function we see the service work does some encoding before sending the following object:
{
browser: navigator.userAgent,
platform: d.SpadePlatform.Web,
time: (new Date).getTime() / 1e3,
ui_context: "browser"
}
Twitch will JSON.stringify(), .replace(), btoa,
Blobify, and then send as the body of a POST request to https://spade.twitch.com.
The rest of the service worker is pretty similar, but there is an unused
object, serviceWorkerOption, which a quick google will give us
https://github.com/oliviertassinari/serviceworker-webpack-plugin.
Continuing our search through the resources of Twitch, we enter the
webpack:// section. We find references to bootstrap,
Redux, along with some misc items.
In the static.twitchcdn.net section, we find a config/settings.js which is
a ~1,500 line long object assigned to window.__twilightSettings and contains,
you guessed it, config settings. Convering things from ad URLs and promotions,
to AB experiments. 1,300 lines of it are experiments config.
static-cdn.jtvnw.net serves all the game box art and user profile pictures.
c.amazon-adsystem.com serves a javascript file which is used for ads. Looking
at the minified source we can see that this file is using Redux,
as we find store.dispatch, store.getState(), and
__REDUX_DEVTOOLS_EXTENSION__. Anyway, it’s ~3,000 lines of ads software, not
much more to say.
Notifications
Twitch connects to a websocket via
wss://pubsub-edge.twitch.tv/v1
Where it sends page views, navigation events as well as establishes listeners for whispers, sub gifts, raids, commerce events, and more. It seems to be the centralized pub-sub connection for any sort of Twitch event, except chat, which is separated and gets its own websocket.
React
Now we are going to dig into the frontend, specifically the React portion of
the site. Earlier we found that Twitch uses Bootstrap, which we can further
confirm by looking at the CSS class names. One thing to note is that
Twitch prefixes all of the bootstrap classes with tw-.
We also see they use https://grsmto.github.io/simplebar/.
Another thing we can see from the React dev tools are the Apollo,
React Router, and a custom withLatencyTracking higher order
components.
Twitch implements code splitting for its React components to reduce bundle size. This means that Twitch will only fetch components that are relevant to a give page.
If we navigate to a channel, Twitch fetches the following JavaScript. Note the pages.channel-$(HASH).js, the current page we are on.
Then if we navigate to https://twitch.tv/directory/following, we fetch
So by chunking, Twitch prevents having a huge bundle, stuffed with components that aren’t relevant to our current page.
But what about CSS? Twitch also chunks CSS. For the following page, Twitch fetches:
In terms of server side rendering, if we curl https://www.twitch.tv/directory
-o index.html && open index.html, we can see that Twitch returns HTML for the top
navbar, and the loading spinner. The necessary CSS is included in a style tag,
while the CSS used in the rest of the site is not loaded. What this means is
that the default HTML in the page is entirely separate from the React site.
However, Twitch does ensure that the og:url meta tags are the same as page
URL, but besides that, the entire page is static.
In the <head> are prefetch link tags,<link
rel="dns-prefetch" href="//example.url"/>, which, you gussed it, prefetch the
dns lookup for a resource you’re going to use. We also
find some <link rel="preload" href="//example.url"/> for ad
related resources.
Twitch also includes relevant <meta/> tags such as their Open Graph
data.
Sidenote: Twitch appears to have an event listener for page focus, so that when you tab back to the page, the title updates. Not sure why this is – maybe a quark of their react routing library necessitates it.
An interesting part of Twitch’s frontend app is their persisting video player, which will popout and float in the bottom left hand corner of the browser when you navigate away from a channel.
Essentially, this works by keeping the React component present in the DOM when a user navigates, while using CSS for position. So if you were to nav from a stream to the settings page, then video player component will still be present.
Seems pretty simple, except that when you navigate to the settings page directly, there is no video player present.
And then we navigate to a different page.
Some interesting note about logging out of Twitch, is that a full page refresh
will occur. This is a simple way to clear session data, but localStorage will
still persist. On login, a full page reload also occurs. I am guessing this is
required by way of their authentication, but could likely be avoided since they
only need to set/remove their auth-token cookie.
Agolia Instant Search
Twitch’s search box uses Agolia, which is a hosted search solution similar to Elasticsearch. On the frontend, the search is composed of a few React components that take the search results as props.
In terms of fetching the data, Twitch contacts https://xluo134hor-dsn.algolia.net/1/indexes/*/queries?x-algolia-agent=Algolia%20for%20vanilla%20JavaScript%203.24.11&x-algolia-application-id=XLUO134HOR&x-algolia-api-key=d157112f6fc2cab93ce4b01227c80a6d which returns a large chunk of JSON in ~60ms. Pretty fast. Although the intitial Agolia query returns most data, including thumbnail urls and user data, Twitch makes a GraphQL query to fetch the current thumbnail for live channels matching the query. This takes about 150ms.
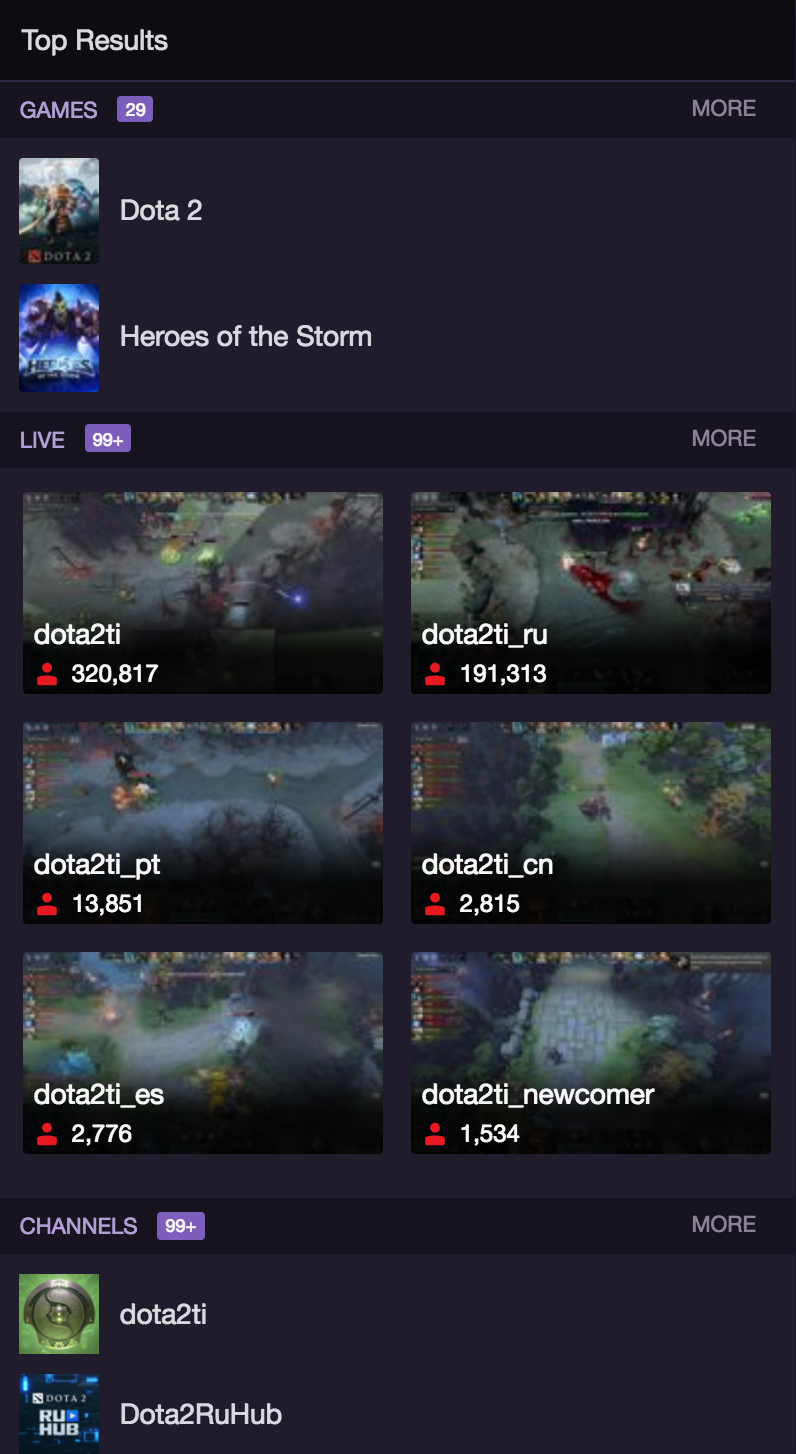
Twitch also uses Agolia for user search in its whisper system.
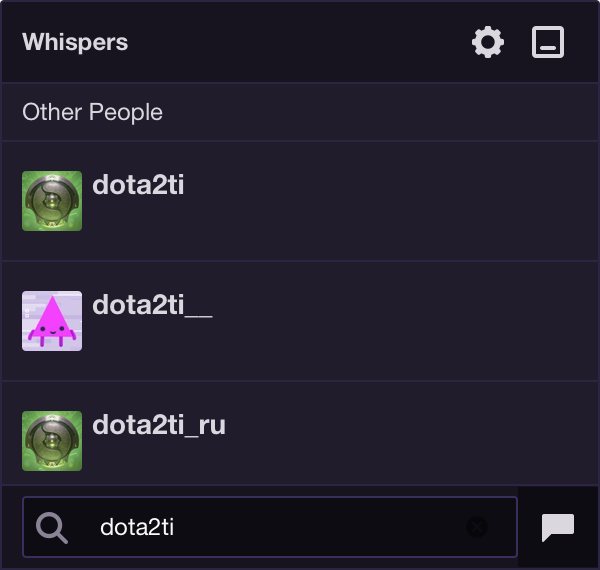
The chat uses GraphQL for sending the whispers.
[{
"operationName": "SendWhisper",
"variables": {
"input": {
"message": "hello",
"nonce": "9a9632f6a0fcda0f5a0df7a6e5f19339",
"recipientUserID": "1234"
}
},
"extensions": {
"persistedQuery": {
"version": 1,
"sha256Hash": "8a5eb4b94c03ef9fe84ab8775885bad00d02ca68a2568af6e1e0a707d971a3f6"
}
}
}]
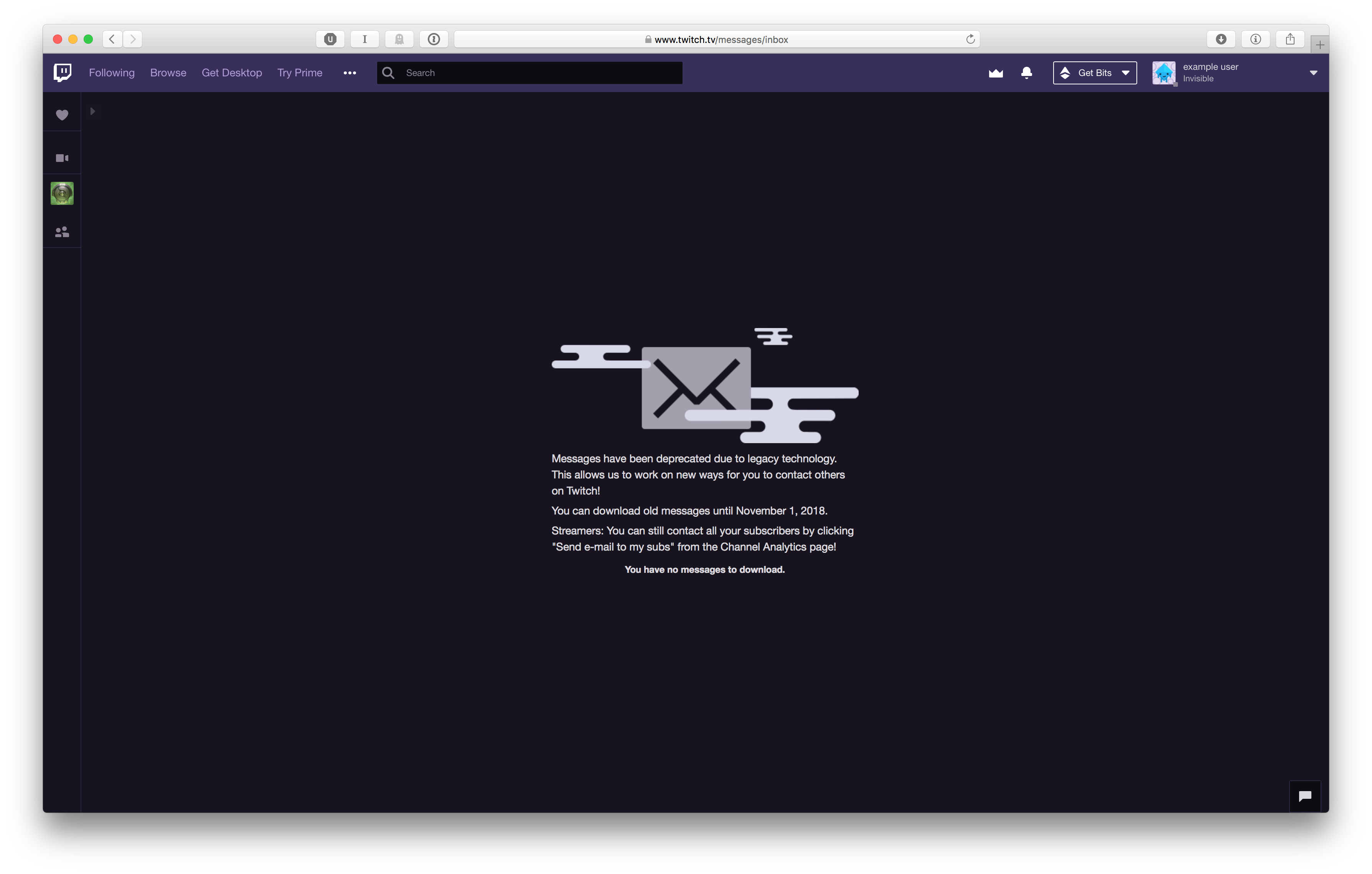
Messages
It turns out that Messages have been deprecated, and that Messages are not the same as Whispers.
Chat
Chat can be viewed by anyone, but requires a login to send messages. There are the concepts of separate chat rooms, which can be restricted to subscribers. Users can send predefined emotes. These emotes can be available to everyone or they can be limited to people who subscribe.
Underneath, Twitch chat uses websockets and talks to an IRC backend. The usage
of IRC is abstracted away from the user, but we can see its traces in the url,
irc-ws.chat.twitch.tv, and also with the initial websocket connection.
When we connect without being logged in, we register with a NICK justinfan41197
(the last bit is just a unique id), and PASS SCHMOOPIIE. These are typically
for an IRC server. Then we connect to the IRC channel for the
stream, so if we are watching https://twitch.tv/dota2ti, we will JOIN #dota2ti.
Messages are sent in the following format:
@badges=;color=;display-name=;emotes=;id=;mod=;room-id=;subscriber=;tmi-sent-ts=;turbo=;user-id=;user-type= :$(USER_NAME)!$(USER_NAME)@$(USER_NAME).tmi.twitch.tv PRIVMSG #$(CHANNEL_NAME) :$(MSG)
// e.g.
@badges=premium/1;color=#8A2BE2;display-name=example_user;emotes=;id=66a3335a-524b-4940-976f-16b2e58a7d4e;mod=0;room-id=35630634;subscriber=0;tmi-sent-ts=1535211960034;turbo=0;user-id=17461;user-type= :example_user!example_user@example_user.tmi.twitch.tv PRIVMSG #dota2ti :Wow that was cool!
On disconnect, Twitch sends a PART message:
PART #dota2ti
Chat is largely siloed from the frontend app. It forgoes GraphQL, and uses plain HTTP requests.
For instance, Twitch calls GET
https://tmi.twitch.tv/group/user/$(CHANNEL_NAME)/chatters to get the current
chat members of a channel. Twitch does end up making a GraphQL request
when you start watching a stream (see below).
[{
"operationName": "ChannelPage_SetSessionStatus",
"variables": {
"input": {
"sessionID": "ade0ad79ef2ae75a",
"availability": "ONLINE",
"activity": {
"type": "WATCHING",
"userID": "121437143",
"gameID": null
}
}
},
"extensions": {
"persistedQuery": {
"version": 1,
"sha256Hash": "8521e08af74c8cb5128e4bb99fa53b591391cb19492e65fb0489aeee2f96947f"
}
}
}]
You may notice that this GraphQL query is missing the query field.
This is because Twitch uses persisted queries, hence the persistedQuery field
in extensions, which allows for using unique IDs in place of a query field.
Something interesting to note is that the link generation, rich embeds (for
links like
Video Streaming
Twitch uses HLS as its streaming protocol along with CloudFront, Fastly, and S3.
Live
Twitch initially fetches:
https://usher.ttvnw.net/api/channel/hls/$(CHANNEL_NAME).m3u8
// which has some interesting query params
allow_source: true
fast_bread: true
p: 6240561
player_backend: mediaplayer
playlist_include_framerate: true
reassignments_supported: false
rtqos: control
sig: e9fbe26616daf5bc600701e544407bf49c1d9bb0
token: {
"adblock": true,
"authorization": {
"forbidden": false,
"reason": ""
},
"channel": "dota2ti",
"channel_id": 35630634,
"chansub": {
"restricted_bitrates": [],
"view_until": 1924905600
},
"ci_gb": false,
"geoblock_reason": "",
"device_id": "13a3960af9ecdf2e",
"expires": 1535307382,
"game": "",
"hide_ads": false,
"https_required": true,
"mature": false,
"partner": false,
"platform": "web",
"player_type": "site",
"private": {
"allowed_to_view": true
},
"privileged": false,
"server_ads": false,
"show_ads": true,
"subscriber": false,
"turbo": false,
"user_id": null,
"user_ip": "50.19.85.132",
"version": 2
}
cdm: wv
and returns an .m3u8 file (see below), a plain text utf-8 format known as M3U for declaring a playlist of media.
Notice how Twitch sends its adblock detection on stream start?
#EXTM3U
#EXT-X-TWITCH-INFO:NODE="video-edge-ee80c0.jfk04",MANIFEST-NODE-TYPE="legacyplus",CLUSTER="jfk04",SUPPRESS="false",SERVER-TIME="1535306185.14",TRANSCODESTACK="2017TranscodeX264_V2",USER-IP="72.93.246.22",SERVING-ID="eafc0af1105e4e8ba7a241c5beaea437",MANIFEST-NODE="video-edge-ee80c0.jfk04",ABS="false",BROADCAST-ID="30091197168",STREAM-TIME="1423.14387012",MANIFEST-CLUSTER="jfk04"
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="chunked",NAME="1080p60 (source)",AUTOSELECT=YES,DEFAULT=YES
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=5113475,RESOLUTION=1920x1080,CODECS="avc1.64002A,mp4a.40.2",VIDEO="chunked",FRAME-RATE=60.000
https://video-edge-ee80c0.jfk04.abs.hls.ttvnw.net/v0/CocDov9gy2FlhSZ19hZK2DVPBM8RX0IWsDojoGtqiQzyh4E-R1dx6ft9X5_KQbZKGtRgBuGLzQkF0BHEszoIwNs8XGKDJcX0Rh6CGqfyhRTNDDFeogSvFnFJrKi5XoKOHgUo2otjtsPYyVwidMMFoqy2PlLWWKVKGhei5Ut3mSTCjeaDWI8BfcIxuLUHzmAoIh6iB5ook_UdLp5bSGBb0tGx0DUitppzN1KDrQfAm8kKgSjoSkvrR1KgXCYvVih805gEIJVTE88wDto8oTYdw0xMvCFUo3grImvymSdPjD4-qGVjB2xDbd4ffzzYHVJPr4pdja_z5KfOgh1Iif2jP5k_woHC-qk9lIWSuO8hlvjUYPoZYmAHV-s_W_UjxK3vxgFSbTRKrVX-tovmFf09oFq-XNC0Av1f6lRIC7wEZjtANGTereUQz_kA3Q8Eof9KwvBapdSKMsSgbv-u84RXX85wt0DQPZg562OjNWhK51muGu11BxDboYnjHGd8s_Zxz7eKa0VtcL_Y2RIQkAOzidc1lAqDCROnOIaaThoMPO5u5U_eDKMilOUY/index-live.m3u8
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="720p60",NAME="720p60",AUTOSELECT=YES,DEFAULT=YES
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=3424135,RESOLUTION=1280x720,CODECS="avc1.77.31,mp4a.40.2",VIDEO="720p60",FRAME-RATE=60.000
https://video-edge-ee80c0.jfk04.abs.hls.ttvnw.net/v0/CoUDJRXK-Sztcjlos9Kw9V1dYgN98eHFcHzPDLYtEXqqZzLCuUFWL8ujnEh_qsmZWTpfnVrsnmgSV_R9iWAPWSgvpElqsvXz2C6mM2bXb7Brcf0B09VLEP_6epz8NHTSifS49mxtq_-EzoCRLKcWPLkZFc7Ok3DgYMW9zqURTyTm87utG3RzQ_pS9jYS5Xl9dv-R6Wljl60OoKSvqCm-uIp-4EUzT4bCNhyMwKsLhsVPbZaLRQqIzyVGlMGj123m8kjQlbNsxo8HR4SV2b9aMLhjYVammNGZlpG0qUPxkragbxWWScg5yUrGomF1a6D6lQr2l65PMKNUd5XDf8l-UtBVHQF-R_6W7E0UNLJKqu3IKgWi8VQQNs-NSGk8Movrq8N5nHvkbiv-jU8ryZ2jPDIh5b42W_D1dMVUa4KX03pUM1e64qAlJv4jqcd-NLEhS1WL15bLb0iRANyPdDft50970kIOTqU-f5R3upqCB--71McQ1rlGLf0USg7Hy4UwnfV2QNEF3m8SEB2j39737NqyQmjJgniw1R4aDOVPY2ez9jNy0U3GmQ/index-live.m3u8
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="720p30",NAME="720p",AUTOSELECT=YES,DEFAULT=YES
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=2374135,RESOLUTION=1280x720,CODECS="avc1.77.31,mp4a.40.2",VIDEO="720p30",FRAME-RATE=30.000
https://video-edge-ee80c0.jfk04.abs.hls.ttvnw.net/v0/CoUDKJD2okGCgP2IaneUItwRZqzeEyHRM4YSH9JxT3eg8F72494XhIbD0Q70O4sa0Pi0xI1nHj8PXuB-T8wln54DlcrqjJBqSXgrizQpgoH3uvbcJSR8jAlsJ3-29TfMPdYStaKslSooqMZrGOirSnNKWa_Kh4x_QdZCyYpk8J-VfxnynvEWrE8aOW2Gh9o1bvrv1SHfUuOJP4ZtPZU8NV83iP_NyO5CRIV00wZrPvBC-eoxLDUpoBmFmybC95GX5IQ9J9OC67bn2eGUfNd8oggV2XgHiStigUVztSlesW9vvzmHeRb5wADaDTCpJ-YMul_UBrUI3TeE5TVjPNg0b68m8UAtFycVlvDVB7horA5LYtwAt0V0Ved1Tht7z284w9hLFgC0DPpaVzq02zQJNP3ePwkFbN1xO2gubnj5pJ8kqxznndujS8fQzAB-2lX15HiZae_eWfk4VxM2c-SvoWFQT1kwJyJGISAArMXTOTxIO2RufBbEz4Zvq9cgGj15hppdHfji-nISEOGaAutRR9obc8bVwiU2K1MaDLHr-7xIxQ7A_YGvmw/index-live.m3u8
-- snip --
Now we fetch the playlists listed in the playlist file, which will give us the URLs for the HLS video segments.
https://video-weaver.jfk04.hls.ttvnw.net/v1/playlist/CskDy5hLEXD7kMQ8E2BikjYwzUQ5qi8jiIgu7geDxNkUQEqBthOCopvXsbP96NQzarY2VP3Ok0hKxqMh1RpGeGOFlC8FtfF5uLdNJWl8yKpS3gPTqL0Ipqd-oorDs5SNiOsmlJmC-DF8WtdFjDr2fyBovNSiqvAm43wg8jASiHoc-4kqN4GtLcHgiG61B981aeDlFn_mMLTQVEWlsV0edrSblcyMNh5c3XmW5rl2H4MIGqljAy7854WdBjuAyNnVNAdgngsMRJc1gXuV8z2KtUFeW0buYO9flIgGLhDfxQ2981NdvQlOrXvgYcdCnSRd28Bq3jxF1e91W2-x4211C6rWBzSYxThA2q83NVYspIi6QR178fewaDLRtgwvn88U6EaAh2UgOd_hPhjTFon7gJd4Y1dPaGFaf8tFocAySus8NKcvtf20ixIOmp1PJneeoKaME-rptFAPxtXCcbCTbU3C-3yAIgY3PeUw_ithf1lc-uAC49Mj5OYNvN3tICZn5ZE2WOSQnS0TGrgaoa8Q2R2ZaqXgaO9_30m-8FjjAqx7rr7GnYb_oiTO6OU6DfC9mGmVrf7SwaJHMQhqz5raddFVtpuFMgKg9pY_thIQMP0P2Ww68WdfvNOMh5-JCxoMROnHHKRo1Y1nFiic.m3u8
With returns the following video segments:
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-TARGETDURATION:6
#EXT-X-MEDIA-SEQUENCE:646
#EXT-X-TWITCH-ELAPSED-SECS:1233.050
#EXT-X-TWITCH-TOTAL-SECS:1263.150
#EXT-X-PROGRAM-DATE-TIME:2018-08-26T17:53:24.317Z
#EXTINF:1.217,live
https://video-edge-ee80c0.jfk04.abs.hls.ttvnw.net/v1/segment/CuEDn-hvM0HhTq7TOEc8XxBpnZm250k-LAjXkxQ5h0213IBSHsE2NdXjsHI35YcEJR48-5Gu5kUyGHM6zLWe7LrNR-tl7OgAeClQ0lG3RiOynfukpXndj8HWMn0NbKoBvW9PyRhr0nQRT3jHQocNXTh13X8SynHlusVkCQ8ANqAxMeatCZ9mTryMMWFuywD6uzdquydFAv2XxQwKUnuZPNkMcFGVq6FX00pOeBvESr66OW7knPEWVHQUyqqdHKu_5dmnd0jUOoR08PL_ocaISX8F8PE2LWMWw9haW254vE8C7zDIEctkE1I3EvcoD1POZIj1lkRJgBklXyVeDq1dp5eMRpqi1yERCBMLp1n_4tZN2SZxq5_WLBFdGu5TJypCgEV9nd2swdft-L3JWAevAiH1aw6pDzbtEi4gzb5P2WJiXJIzqOF8oVi0xhTa08Rxgn4G2ftj9Xm42M4NMRIoksPORKZBy9WMvTqkx0n6D_jkNWm66vqWN1znp0f18n8fpicL774tUecsUCG1_DTBBYpH3RDaerqlWDd1Buez8TwA_v4RS_iFc0R9a6RZsMw7nTD-SegvYa_KHgPZVC4mKxSqjAoFdwjC7ShVMaYfCHkiH0x_oxhOll71IbZkApEt2zW1hhIQMaxUzcFmYorDgaBVLDmzpBoMsKQQBE5Xt-vp2R1C.ts
#EXT-X-PROGRAM-DATE-TIME:2018-08-26T17:53:25.534Z
#EXTINF:1.850,live
https://video-edge-ee80c0.jfk04.abs.hls.ttvnw.net/v1/segment/CuEDzRhSintGTeLUEpRsN5mxnaYDjPYNa6F5R72cZxKM_FQSCkzmLHwSNyrwmsJUC2y90N9Vf_HOS3znTLul4a7gj4HUcPpIYq4ybbTbLMx7_p5cBtpkL3KkBDNIPFcxZQr5LXh9VQ7WLBQ_doZ1Bp_HTiiMgihv7vhMIFK1tdwgkcXRk5t6_gi5O2yJ8r9wVd4v7hE8MbWtTak2ce-FvDmRlzo0ZXksead-tjhz6ZhOM5fra7EaWy-QYd0B3pdB82bhQjXaeCgJNKYmgh0hVs5Y5rZFgrD-YgLK2UbBg9wbxW7q3QuRwstLJzXrSR2RGOUwp0VHOtpaXi39DUgYlyHaTHjw1rQ1hzovvEWoizuRaIFh6pj73vh-MxA0uSsmbvMIYkCvtKm9uAOVrkoZqccnhqhjLxeNzcmp5iZCHYRgxS5ahyn_MvjwpaF355ncW_7wlln0VuiXODgcDEvSww8y7G91V_Rfwb3S8RJQ3oFLYtWe1IrwcqAaJStcgwvQxC4TY4KB3QiroAlFcgEm5JyivSWfUILheevlBYvWr5VqMEzPOd2O-coPKGfAKQ3JRWc9LmhX4LrZgCqOqUQC3zkW5084YY1IMzPDQ70Ty32M17DnsiIlphwQ51pVgoSQnLSJDBIQCQiVYigozes3i6XEsDEi-BoM-4NjyG_OSozMi0BW.ts
#EXT-X-PROGRAM-DATE-TIME:2018-08-26T17:53:27.384Z
#EXTINF:1.433,live
https://video-edge-ee80c0.jfk04.abs.hls.ttvnw.net/v1/segment/CuED9JyCn4a1-Jl11NC7esW7jRv-sjpqKQen2OEMre6REYEg1ATCLAtTcnSbc6PzQu3zvr81dd8LjomGbP7MtedcUl04b1XahjZEQaStcOFyiY7CnUbLn5OA5L8mnHMezKB6eI-fguuKyC1nGPcmgVQEb42psjOrGeBwd-GznC08IRdxGOxKTqK7pZMF5gevjtgJ9kwAKVUvclcn9mpY1Svewu7KusxTwNIJawhahgTXuLv2i9hqz6Griwj4xM4hZVTTw9grp2GDoFaRmJ4jhhTdDnI1ckTYqm9f_9XReIA2FTVqfN5s3C-sqvKf0Qj9OZUUAiBbcDnCU3mpjrRY44KbCkBI9h00vUlUab8ClG4R0w21bN6teOOtWdEvca--ggl_20Hw8K7ZdYiYRtCWlMb10UnlF4ZIgN4ZIR4dngrVu6Ei5bFp-riHNhMyAUK3yNUUZoy2QqxK_BT4rvlkaah4p-mqTJNIWCPC7-h4X-MFhTwvfp5BF-bjBzGWte8SPkAIe6SMs_gcRTo2GK4JQEQIs0H5dsN_2Ya8AZOK0tJaDwmTJnfJnN35xEQKYvYfAwQKTuT5n7FJ_Sovn4xKSRNOe-gzCtTaRJyxdsj4uWeEWEOmzFdAxvWa4Z93st8qWufZrBIQaybV4ILHBsCUup7AOBbQ3RoMmVCB5KDHKrNgZf2a.ts
#EXT-X-PROGRAM-DATE-TIME:2018-08-26T17:53:28.817Z
#EXTINF:1.517,live
https://video-edge-ee80c0.jfk04.abs.hls.ttvnw.net/v1/segment/CuEDlhDOFPDUvyBuEmOS6EN95eVHeDWjHCd8LKUqgosUNRJb7XPJbgUDdQTY00pW1Sv4zz4BE4jfFPnlmeQUXYzSxXO7AOV3KBfGmmJ5HD-iyux_YFG_fm9XfZrjqMWDH8ShGqrvdVpoX5o8PpWSbmugMkkRmUBcB_SAwHWrbqD3s59x9DDIdPg1Rnjcs8UNLKt525_m9Usi0AEBcs-c0md-ZiPT2ub51PGARc2R_OU1TBi63bgYAjCyFnhufcYnN8audAxKItwlbcCbPSPuLhY-Istr5Prxg5cQFoy_6CgboSlIEXjQ1wViLi4cS3QSHlkHP0bT7cQIOwXsCfJ4f_Ng2ZtTzKxhnBRRTg3a9hcBzXFQxUt2yAU5vhKrOBMfnq-xXqDf0Swb8Yee1JPT6EtrhX5s4be2a9NV2A5CMXcMV8s4wI7TYO8euyLh6s7VjwF0REoSAIddf1BQ5kvhjLVGc5GS7LjLsVCUIEwCwz8pc0UZ0bwbesRPbmnXRTmcSCWaTJB6qIktye6jiuu7NykSPOU9W5RyJTRy8R4FXEYC8jluy4FW8_HKH4W4oEUAhF9_K9IJpskH_xMZAC56KfAwQ7LvZo76c5NO0SjfLt_oPQroAz1vvFN4GoDOrc2lcMwAGhIQj3sXhbxmK2bXJp-PmYCGVhoMbM5XJtzuujVFi8FC.ts
-- snip --
Then we just fetch those video segments, and repeatedly call the same .m3u8
URL to get more segment URLs.
Reruns
On initial connect to a channel showing a rerun, Twitch POSTs a blob of data to https://video-edge-3194a4.sjc02.hls.ttvnw.net/v1/segment/$(SEGMENT_ID).ts, and gets a 204 back.
Then, like live broadcasts, we contact the usher URL
https://usher.ttvnw.net/api/channel/hls/$(CHANNEL_NAME).m3u8
and then fetch the subsequent playlists from:
https://video-edge-ee7fbc.jfk04.abs.hls.ttvnw.net/v0/$(UNIQUE_ID)/index-live.m3u8
and fetch the segments
https://video-edge-ee7fbc.jfk04.abs.hls.ttvnw.net/v0/$(UNIQUE_ID)/index-$(SEGMENT_ID).ts
Vods (Videos)
Vods are usually past streams that have been kept and stored for replay, although it is also possible to upload videos directly to Twitch.
On viewing a video page, Twitch will send GET requests to:
https://usher.ttvnw.net/vod/$(VIDEO_ID).m3u8
// and
https://vod-metro.twitch.tv/$(CHANNEL_ID)_$(VIDEO_ID)/$(VIDEO_QUALITY)/index-dvr.m3u8
// or sometimes via a CDN (seems that there is some AB testing going on)
https://fastly.vod.hls.ttvnw.net/$(CHANNEL_ID)_$(VIDEO_ID)/$(VIDEO_QUALITY)/index-dvr.m3u8
Which give us the segment URLs to fetch.
Twitch fetches the videos in chunks that can range from a couple hundred KBs to
around ~9MB, but this is only a small sample. The size of the chunks depends on
your video setting. The 160p option returns ~370KB chunks.
https://vod-metro.twitch.tv/$(CHANNEL_ID)_$(VIDEO_ID)/$(VIDEO_QUALITY)/$(CHUNK_SERIES_ID).ts`
// VIDEO_QUALITY will be set to 'chunked' if you are viewing at source resolution
// some examples:
https://vod-metro.twitch.tv/dccc6d6c0e33975cda7a_dota2ti_30075157776_948322792/chunked/1086.ts
https://vod-metro.twitch.tv/dccc6d6c0e33975cda7a_dota2ti_30075157776_948322792/720p60/1087.ts
https://vod-metro.twitch.tv/dccc6d6c0e33975cda7a_dota2ti_30075157776_948322792/720p30/1087.ts
https://vod-metro.twitch.tv/dccc6d6c0e33975cda7a_dota2ti_30075157776_948322792/160p30/1083.ts
Unlike streams, vods have popover images in the video scrubber, for some reason reruns don’t have these. Twitch fetches both a high quality and low quality versions of these images. When you scrubb further into the video, Twitch will fetch the higher indexed storyboards.
https://vod-storyboards.twitch.tv/$(CHANNEL_ID)_$(VIDEO_ID)/storyboards/$(STORYBOARD_ID)-$(STORYBOARD_QUALITY)-$(STORYBOARD_INDEX).jpg
// example
https://vod-storyboards.twitch.tv/615d2b9305587c72317d_naysayer88_29693719888_924527656/storyboards/290847324-low-0.jpg
Twitch will periodically send a POST request to
https://video-edge-3194a4.sjc02.hls.ttvnw.net/v1/segment/$(SEGMENT_ID).ts
Which I assume is to sync up the timing of chunks.
If you are logged in, Twitch also keeps track of what you are watching by
periodically sending a PUT request to
https://api.twitch.tv/v5/resumewatching/user/$(USER_ID) with the following
data:
{
position: 123127,
type: 'vod',
video_id: 'v594876595',
}
The responses from
Server: AmazonS3
Via: 1.1 fd4983be77ace22659323918c5b30f1f.cloudfront.net (CloudFront)
X-Cache: Hit from cloudfront
Something to note is that the URL for fetching the index-live.m3u8 is the
same for a given channel. The only difference between each response are the
Date:, Expires:, and Tenfoot-Context: headers. Not sure what the
Tenfoot-Context: header is for, it contains a varying hex number e.g.,
0x275af65e09234ee8.
Clips
Clips are segments of a stream that are saved. Similar to videos, but limited to <1.5 mins in length (this seems to vary slightly).
To create a clip, a user must be signed in and they hit the create clip button in the video player (video player must be an unpaused stream).

On click, Twitch sends two requests:
1. GET request to https://clips.twitch.tv/api/v2/clips
with headers:
Access-Control-Request-Headers: authorization
Origin: https://www.twitch.tv
Pragma: no-cache
Accept: */*
Cache-Control: no-cache
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/11.1.2 Safari/605.1.15
Referer: https://www.twitch.tv/dota2ti
Access-Control-Request-Method: POST
getting a response of:
Content-Type: application/json; charset=utf-8
Date: Tue, 28 Aug 2018 01:50:41 GMT
Connection: keep-alive
Access-Control-Allow-Methods: DELETE
Access-Control-Allow-Origin: *
Content-Length: 0
Accept-Ranges: bytes, bytes
Vary: Accept-Encoding, X-ENV, X-PLAYER, X-TWILIGHT
Access-Control-Allow-Headers: X-Requested-With,Content-Type,Authorization,Distinct-Id
X-Timer: S1535421041.406038,VS0,VE81
X-Served-By: cache-sea1043-SEA, cache-iad2128-IAD
X-Cache: MISS, MISS
X-Cache-Hits: 0, 0
2. POST request to https://clips.twitch.tv/api/v2/clips
with a payload of
MIME Type: application/x-www-form-urlencoded
broadcast_id: 41110642525
channel: dota2ti
offset: 1970
play_session_id: ydTOJak9Cnk8vKqh1Cu0zl43szJrrxWo
player_backend_type: mediaplayer
vod_id
with headers
Content-Type: application/x-www-form-urlencoded
Origin: https://www.twitch.tv
Host: clips.twitch.tv
Pragma: no-cache
Accept: */*
Connection: keep-alive
Accept-Encoding: gzip, deflate
Accept-Language: en-us
DNT: 1
Authorization: OAuth w8oa8myl28ttbx9r6hms9ayk8n
Content-Length: 141
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/11.1.2 Safari/605.1.15
Referer: https://www.twitch.tv/dota2ti
Cache-Control: no-cache
receiving a response with headers
HTTP/1.1 201 Created
Content-Type: application/json; charset=utf-8
Date: Tue, 28 Aug 2018 01:50:41 GMT
Cache-Control: no-cache, max-age=0, s-maxage=0, no-store
Access-Control-Allow-Origin: *
Connection: keep-alive
Content-Length: 1939
Accept-Ranges: bytes, bytes
Vary: X-ENV, X-PLAYER, X-TWILIGHT
X-Timer: S1535421042.588825,VS0,VE305
X-Served-By: cache-sea1025-SEA, cache-iad2128-IAD
X-Cache: MISS, MISS
X-Cache-Hits: 0, 0
and data
{
"broadcaster_channel_url": "https://www.twitch.tv/dota2ti",
"broadcaster_display_name": "dota2ti",
"broadcaster_id": "41463454",
"broadcaster_login": "dota2ti",
"broadcaster_logo": "https://static-cdn.jtvnw.net/jtv_user_pictures/a3ab938b-5c7f-470f-bfa3-052aa648ab2f-profile_image-300x300.png",
"broadcast_id": "30110642464",
"curator_channel_url": "https://www.twitch.tv/example_user",
"curator_display_name": "example user",
"curator_id": "200525315",
"curator_login": "example-user",
"curator_logo": "https://static-cdn.jtvnw.net/user-default-pictures/b83b1794-7df9-4878-916c-88c2ad2e4f9f-profile_image-150x150.jpg",
"preview_image": "https://clips-media-assets2.twitch.tv/$(BROADCAST_ID)-offset-2948-preview.jpg",
"thumbnails": {
"medium": "https://clips-media-assets2.twitch.tv/$(BROADCAST_ID)-offset-2948-preview-480x272.jpg",
"small": "https://clips-media-assets2.twitch.tv/$(BROADCAST_ID)-offset-2948-preview-260x147.jpg",
"tiny": "https://clips-media-assets2.twitch.tv/$(BROADCAST_ID)-offset-2948-preview-86x45.jpg"
},
"game": "Dota 2",
"communities": [],
"created_at": "2018-08-28T02:06:54Z",
"title": "[EN] The International 2018 Main Event",
"language": "en",
"url": "https://clips.twitch.tv/$(CLIP_SLUG_NAME)",
"info_url": "https://clips.twitch.tv/api/v2/clips/$(CLIP_SLUG_NAME)",
"status_url": "https://clips.twitch.tv/api/v2/clips/$(CLIP_SLUG_NAME)/status",
"edit_url": "https://clips.twitch.tv/$(CLIP_SLUG_NAME)/edit",
"embed_url": "https://clips.twitch.tv/embed?clip=$(CLIP_SLUG_NAME)",
"embed_html": "\u003ciframe src='https://clips.twitch.tv/embed?clip=$(CLIP_SLUG_NAME)' width='640' height='360' frameborder='0' scrolling='no' allowfullscreen='true'\u003e\u003c/iframe\u003e",
"view_url": "https://clips.twitch.tv/api/v2/clips/$(CLIP_SLUG_NAME)/view",
"id": "498203828",
"slug": "MagnificentCalmStapleTerrier",
"duration": 0,
"views": 0
}
Then Twitch opens a new window for you with the URL
https://clips.twitch.tv/$(CLIP_SLUG_NAME)/edit, which then
redirects to https://clips.twitch.tv/create
In a surprising turn, Twitch fetches the video data for clip creation as a plain .mp4.
Above we can also see the status_url, which is used for polling to see if a clip has processed.
After selecting your length and adding an appropriate title, Twitch will send a GraphQL query to create the clip:
[{
"operationName": "PublishClip",
"variables": {
"input": {
"segments": [{
"offsetSeconds": 48,
"durationSeconds": 30,
"speed": 1
}],
"slug": "$(CLIP_SLUG_NAME)",
"title": "Test"
}
},
"extensions": {
"persistedQuery": {
"version": 1,
"sha256Hash": "f04b575262faae00ee7566fc6a510f5adef93c8d114b666cf549fa5a870021fd"
}
}
}]
After some processing (usually instantaneous), share options will pop up. Note, the initial diceware slug name is what is used from initial creation to sharing.
Users can manage their created clips via:
https://www.twitch.tv/$(USERNAME)/manager/clips
Which is a pretty staightforward React page that uses GraphQL to fetch the clip data.
A request made to
https://r.nexac.com/e/getdata.xgi?foo=bar
I think it might be related to adblock detection. Perhaps, if the Ad network requests fail, but this request doesn’t, then Twitch knows you are running adblock software. Turns out, this network request is made on all pages – only noticed it now.
In terms of fetching video data, Clips fetch their video in the same way as a live stream, they also use GraphQL to fetch the chat messages (this is a recent addition) along with some other, less essential data.
2 Factor
Sudo
Configuring 2 Factor falls under a sudo required operation. When trying to complete a request that requires sudo, you will be redirected to:
https://passport.twitch.tv/sessions/new?client_id=settings_page&redirect_path=https%3A%2F%2Fpassport.twitch.tv%2Fdisable_2fa%2Fnew&sudo_reason=DEFAULT&username=example_user
Which sets a cookie
set-cookie: passport_requested=uwr1m5psv3bztdhz45lfxq50cwint83r; Max-Age=0
Then by filling out the form at
https://passport.twitch.tv/two_factor/new?client_id=settings_page&code=eyJhbGciOiJIUzUxMiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJodHRwczovL3Bhc3Nwb3J0LnR3aXRjaC50diIsInVpZCI6IjIwMDUyNTMxNSIsImxvZ2luIjoiZXhhbXBsZV91c2VyIiwiZXhwIjoxNTM1NTA4MzE4LCJpYXQiOjE1MzU1MDc1OTgsImF1ZCI6InNldHRpbmdzX3BhZ2UiLCJzY29wZSI6InRva2VuX2Zsb3ciLCJhdXRoeV9pZCI6MjI2NzYyNn0%3D.JD6j18EjfuGO-fK6Az7eZcjvHJSx5lQte11-N2P6OCGNJHQ6YSS3OoWrrR4CfWrZyYE_I0fHkWXBfJ7TV1LT3Q%3D%3D&embed=false&origin_uri=&redirect_path=https%3A%2F%2Fpassport.twitch.tv%2Fdisable_2fa%2Fnew&sudo_reason=
and hitting send. We have our sudo cookie along with several others set.
As expected, we send a CSRF token to the backend, but this token is label _goji_csrf created via Goji, specifically goji/crsf.
Also, you may have noticed that the code url param looks base64’d.
>>> import urllib
>>> import base64
>>> raw_data = "eyJhbGciOiJIUzUxMiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJodHRwczovL3Bhc3Nwb3J0LnR3aXRjaC50diIsInVpZCI6IjIwMDUyNTMxNSIsImxvZ2luIjoiZXhhbXBsZV91c2VyIiwiZXhwIjoxNTM1NTA4MzE4LCJpYXQiOjE1MzU1MDc1OTgsImF1ZCI6InNldHRpbmdzX3BhZ2UiLCJzY29wZSI6InRva2VuX2Zsb3ciLCJhdXRoeV9pZCI6MjI2NzYyNn0%3D.JD6j18EjfuGO-fK6Az7eZcjvHJSx5lQte11-N2P6OCGNJHQ6YSS3OoWrrR4CfWrZyYE_I0fHkWXBfJ7TV1LT3Q%3D%3D"
>>> data = urllib.parse.unquote(raw_data)
>>> base64.b64decode(data)
b'{"alg":"HS512","typ":"JWT"}{"iss":"https://passport.twitch.tv","uid":"200525315","login":"example_user","exp":1535508318,"iat":1535507598,"aud":"settings_page","scope":"token_flow","authy_id":2267626}'
we can make it a little more readable
{
"alg":"HS512",
"typ":"JWT"
}
{
"iss": "https://passport.twitch.tv",
"uid": "200525315",
"login": "example_user",
"exp": 1535508318,
"iat": 1535507598,
"aud": "settings_page",
"scope": "token_flow",
"authy_id": 2267626
}
JWT, plain and simple.
Note: https://passport.twitch.tv is a seperate, plain HTTP, HTML, non-SPA site. Based on some CSS classes, I believe passport is called Kraken, compared to the main Twitch site which is called Twilight.
Enable
-
send phone number via https://passport.twitch.tv/register_2fa/new
-
enter verification code at https://passport.twitch.tv/enable_2fa/new
Note: Twitch has some connection directly with Authy, so if you have Authy connected to your phone, Twitch will automatically use it.
- end up at the success page https://passport.twitch.tv/2fa_enabled/new
Disable
Usage
When authenticating Twitch POSTs your username, password, and client_id to
https://passport.twitch.tv/login. With 2 factor enabled, this results in a
400 and we get the option to submit our Authy / SMS code.
The response of the initial 400 request, after base64 decode:
{
"error_code": 3011,
"error_description": "missing authy token",
"captcha_proof": '{"alg":"HS512","typ":"JWT"}{"iss":"https://passport.twitch.tv","iat":1535593181,"aud":["captcha_proof"],"sub":"example_user","exp":1535593481}',
"sms_proof": '{"alg":"HS512","typ":"JWT"}{"iss":"https://passport.twitch.tv","uid":"200525315","login":"example_user","exp":1535593901,"iat":1535593181,"aud":"kimne78kx3ncx6brgo4mv6wki5h1ko","scope":"token_flow","authy_id":2568189}'
}
Sidenote: Twitch’s JWTs expire after 5 minutes.
On submitting our 2-factor code, Twitch POSTS the authy_token, username,
password, client_id, and captcha.
On success, we get sudo, login, name, api_token, and a few other auth
related cookies set.
After authenticating, Twitch makes a CoreAuthCurrentUser GraphQL request,
which doesn’t get a response or sent any headers – not sure of its purpose.
If you forget your 2-factor you have to contact Twitch support since there aren’t any recovery codes like other services.
OAuth Connections
Twitch has a the ability to link your Steam, Blizzard, and a few other accounts to your Twitch account.
If we go to the connections page and hit one of the connect buttons, a new window will open for the other service’s login, allowing us to link our account on the other service.
So if we want to link Steam, we hit the Steam connect button and
https://steamcommunity.com/openid/login?openid.claimed_id=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier_select&openid.identity=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier_select&openid.mode=checkid_setup&openid.ns=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0&openid.realm=https%3A%2F%2Fapi.twitch.tv&openid.return_to=https%3A%2F%2Fapi.twitch.tv%2Fv5%2Fsteam%2F200525315%2Fcallback%3Fclient_id%3Djzkbprff40iqj646a697cyrvl0zt2m6
opens in a new window.
If we decode the url and break it onto new lines it becomes more clear what is going on:
https://steamcommunity.com/openid/login?
openid.claimed_id=http://specs.openid.net/auth/2.0/identifier_select&
openid.identity=http://specs.openid.net/auth/2.0/identifier_select&
openid.mode=checkid_setup&
openid.ns=http://specs.openid.net/auth/2.0&
openid.realm=https://api.twitch.tv&
openid.return_to=https://api.twitch.tv/v5/steam/$(USER_ID)/callback?client_id=jzkbprff40iqj646a697cyrvl0zt2m6
Generally a connection works like follows:
- open new window with OAuth login screen and an event listener for a
messageon the current window. - login in the popup window
- OAuth provider redirects to the
return_tourl, which will send a request to Twitch backend and thewindowwill also send a message to Twitch saying connection sucessfull.
After connecting, Twitch sends a GraphQL request fetching the connection info.
To delete the connection, Twitch sends a DELETE request to:
https://api.twitch.tv/v5/blizzard/$(USER_ID)
And then sends another GraphQL request to refetch the connection data.
Commerce
On Twitch users can purchase Bits, currency that can be given to Streamers, subscriptions, monthly payments to streamers, as well as Twitch Prime, which comes with a Amazon Prime subscription.
Bits are purchased by clicking the bits tab.
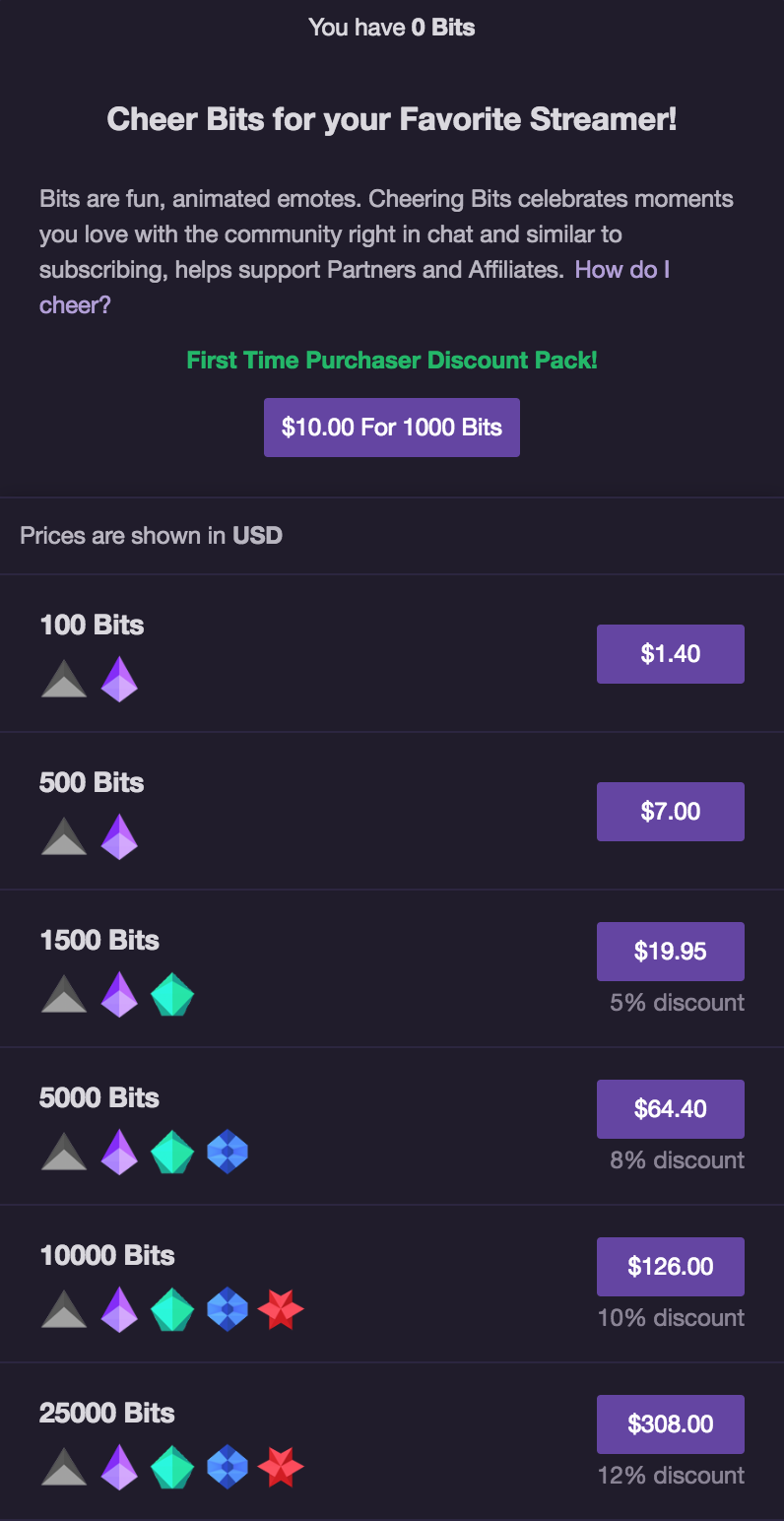
If we decide that we can’t settle for anything less than 25,0000 bits, then a new window will open at
https://www.twitch.tv/bits-checkout/select?asin=B01G4BISOS&br_id=&locale=en-US
where the asin corresponds to the quantity of bits you are buying.
There is a similar message event listener setup to trigger a GraphQL to update bits related info after a purchase, or an attempt at a purchase is made.
Note: this buying window is also a React app.
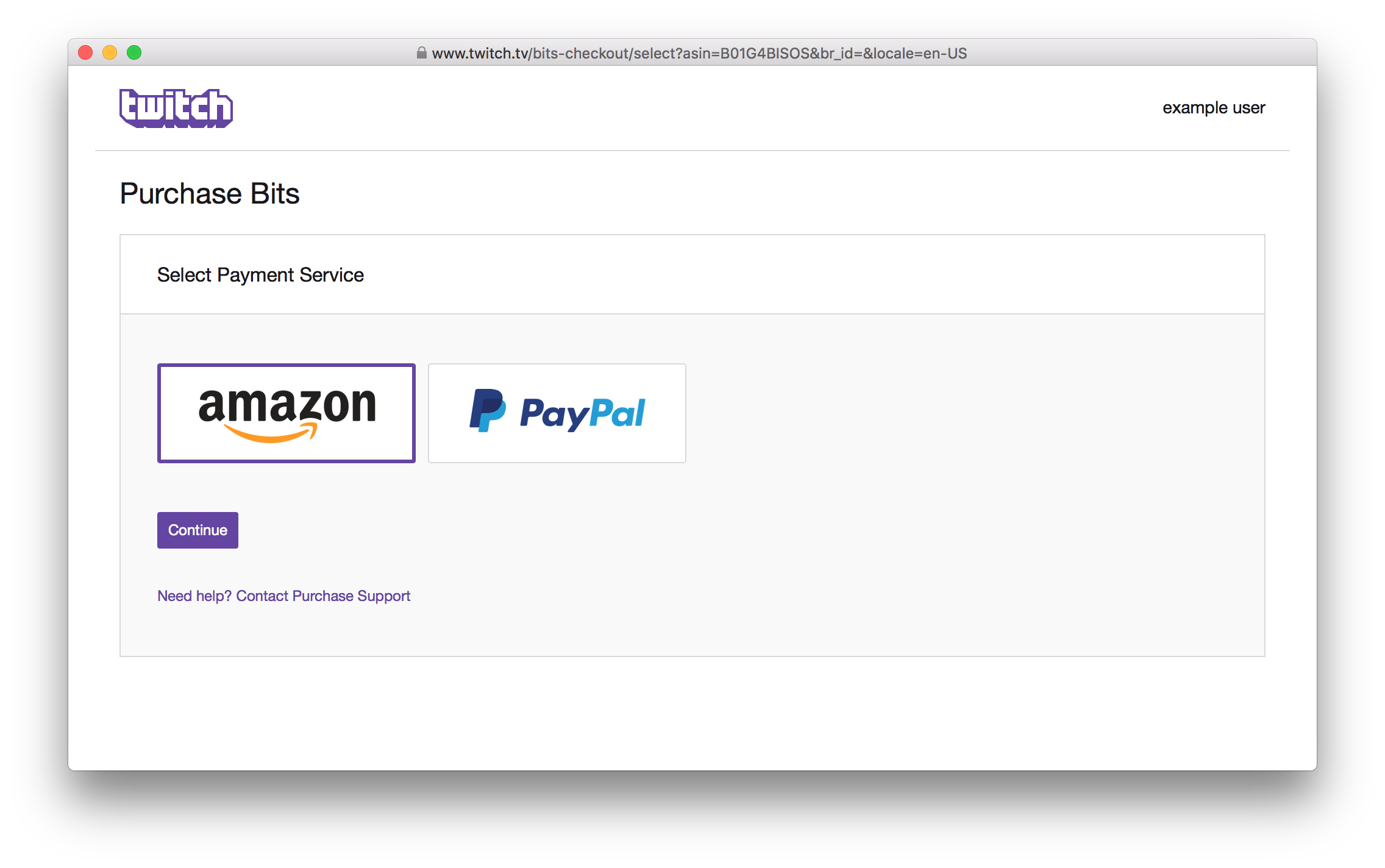
The services use a similar OAuth set up as discusses previously in the connections section.
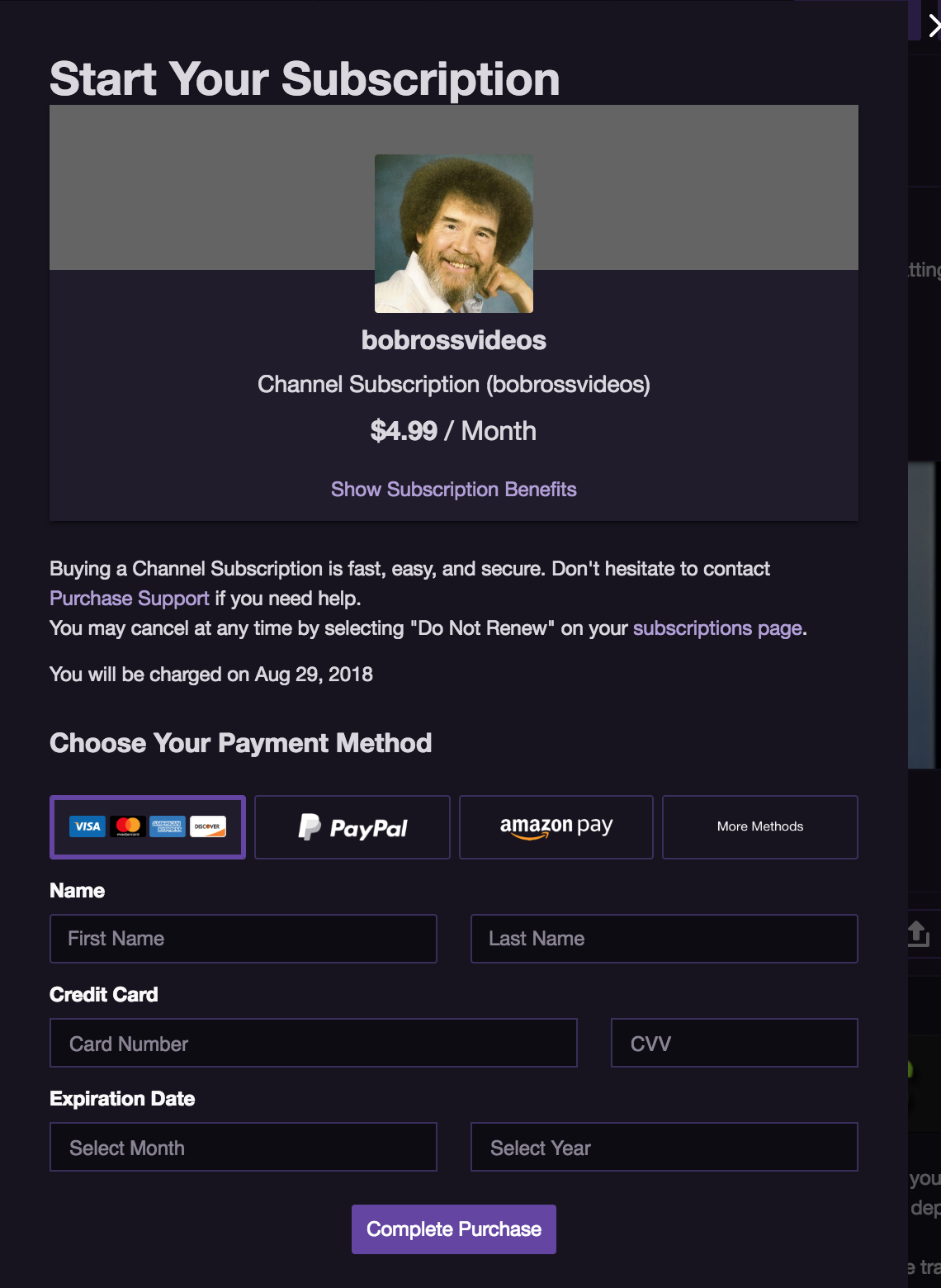
Purchasing subscriptions is more integrated into the site, and has a lot more options, but all the purchase methods work in a similar way to previously discussed.
Settings Page
The settings page is pretty plain. In a departure, settings primarily uses a REST api and makes a couple calls via GraphQL.
Its consists of pretty basic CRUD operations.
Video Producer
Although video content on Twitch is primarily created through streaming, users can also upload videos directly through https://www.twitch.tv/manager.
A frontend thing to note is that Twitch creates their file dropzone by using CSS to stretch an input element as well as using the HTML Drag and Drop API.

The upload process works likes follows:
- select file to upload
-
Twitch sends api request to
https://api.twitch.tv/kraken/videoswith the following data, initialting a multipart upload to S3{ "channel_id": $(USER_ID), "title": "A pretty cool video", "viewable": "private", "create_premiere": true }getting in response:
{ "upload": { "token": "kb2OTgG8OIYZ_K6KLWIvC8R.FmHakt.UFmA2hRNoCPV3E.ALo.60yoBEBFedRjgyT0G9DzsCi.WIZt9JLOjk1KqglapSdWYJG8ozDgyWnbp_QNtevoEc0DtuB1WFp27_BTBSRebCWiIpWr40F4DdVqEhBLoA2oKCKwXDuZLiE3A-", "url": "https://us-west-2.uploads-regional.twitch.tv/upload/$(VIDEO_ID)" }, "video": { "title": "A pretty cool video", -- snip -- "status": "created", "url": "https://www.twitch.tv/videos/$(VIDEO_ID)", "viewable": "private", -- snip --- "premiere": { "id": "", "status": "unscheduled", "event": null }, } } -
Twitch sends chunk(s) to s3 via a PUT request using the
upload_tokenandvideo_idcreated via part 2.https://us-west-2.uploads-regional.twitch.tv/upload/$(VIDEO_ID)?part=1&upload_token=$(UPLOAD_TOKEN)In my case, the 1.5MB file was small enough to fit in one chunk.
Another note is that while I am closest to us-east-1, Twitch chose us-west.
-
Complete multipart upload
Twitch completes the multipart upload with a POST request to:
https://us-west-2.uploads-regional.twitch.tv/upload/$(VIDEO_ID)/complete?upload_token=$(UPLOAD_TOKEN) -
Poll for Updates
While Twitch doesn’t provide a progress bar, they do poll for updates to see if the transcoding is complete. Their endpoint to fetch video data is used to poll video transcode status. When polling, Twitch checks if the
statusproperty in the response is set to'transcoding'. Eventually, thestatuschanges to'recorded', the polling stops, and Twitch updates the page with its fetched info.https://api.twitch.tv/v5/videos/$(VIDEO_ID)
In total, Twitch took about 2 minutes to upload and transcode a 1.5 MB, H.264 encoded video.
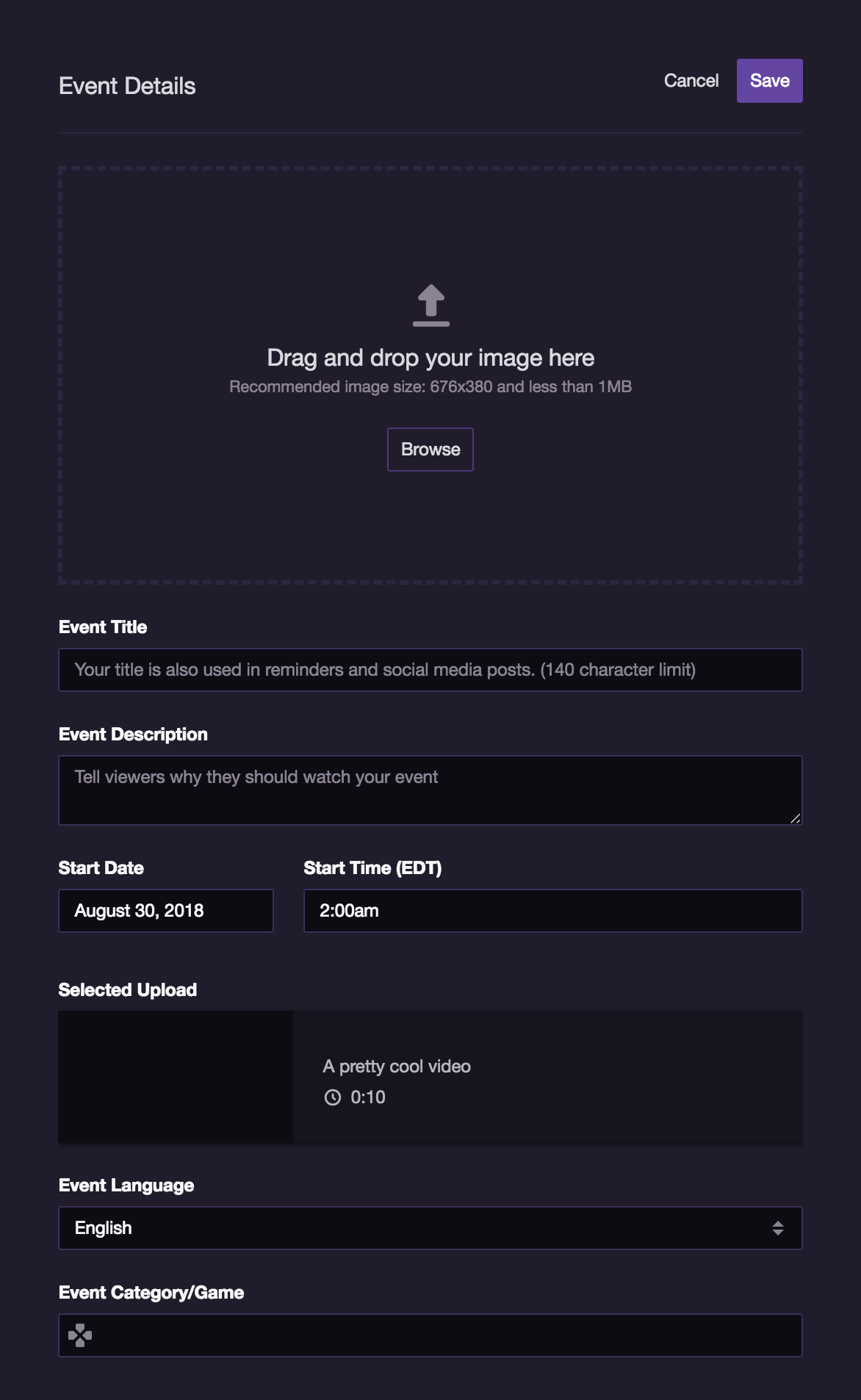
After uploading, the video is private until you ‘premiere’ it, which is event that you can schedule with a cover image and everything.
The cover image is base64 encoded and uploaded in a request body.
WASM Service Worker
There as an additional service worker to the one we already discussed. This one involves both WASM and js.
https://cvp.twitch.tv/2.6.3/wasmworker.min.js https://cvp.twitch.tv/2.6.3/wasmworker.min.wasm
The .wasm is ~233kB, and the .js is ~23kB.
By looking at the js, we can see that this service worker was compiled down via Empscripten, and that the main job of the javascript is to fetch and load the wasm worker.
The job of the webworker isn’t entirely clear. There are some references to analytics, the video player settings, media codecs and more.
At 233kB, you would expect the worker to be quite capable, so I am guessing it’s a multitasker.
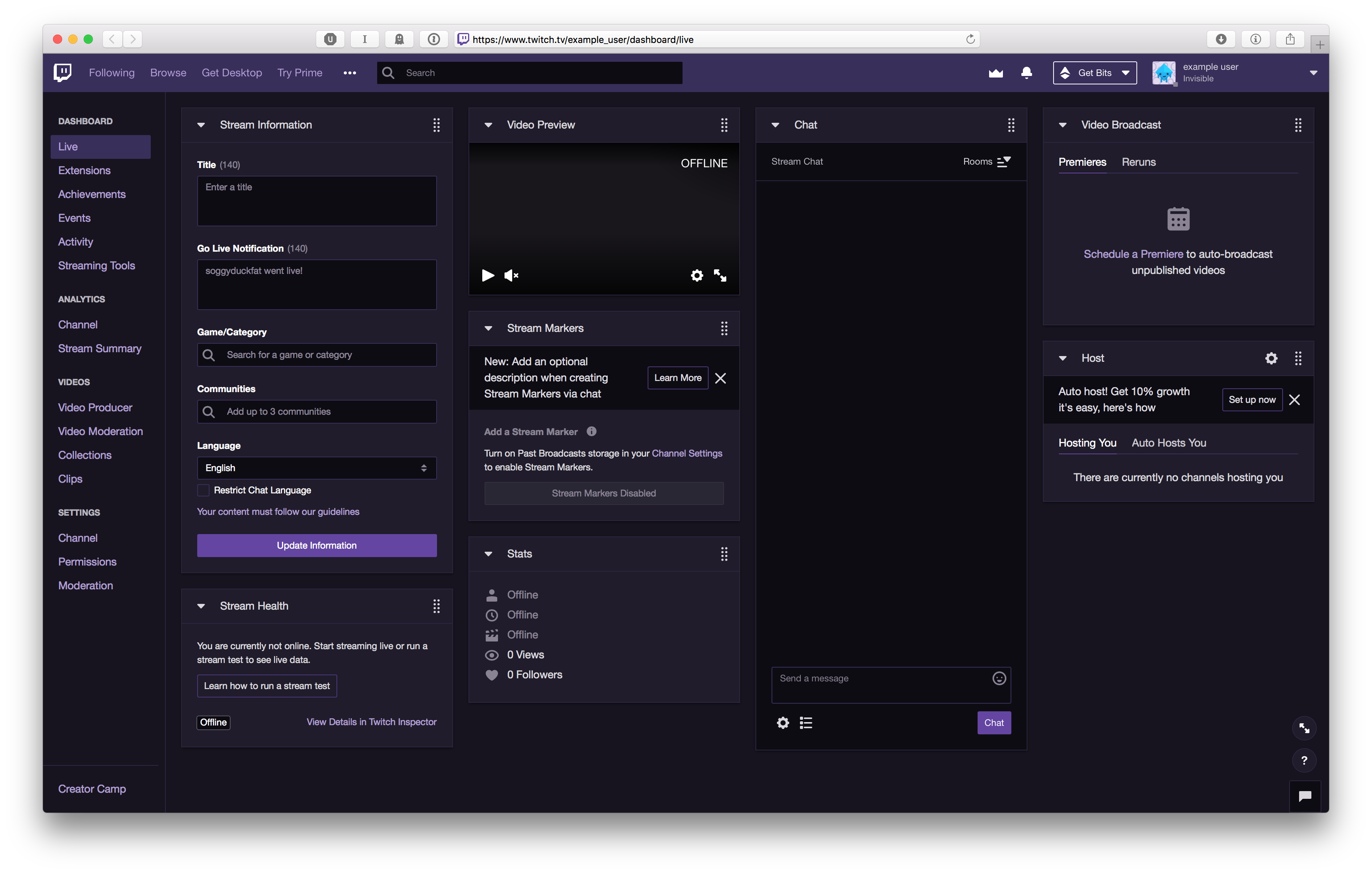
Dashboard
The dashboard is used when streaming video content.
To fetch content the dashboard uses primarly GraphQL with some additional REST endpoints thrown in.
There is an ability to rearrange the cards, although the configuration is only stored locally.
The dashboard has its own video player of the stream, along with a chat, which use the same setup as previously discussed. The rest for the most part is a CRUD.
TL;DR
React.js based SPA frontend, using GraphQL for data transfer, websockets for its pub-sub and IRC based chat. Agolia for search. HLS for video streaming – with a sizable pinch of user tracking throughout.